¶
Link do strony: https://nsdap.kamienikupa.com
¶ 1.Tło
¶
USA otworzyły dostęp do baz mikrofilmów z Berlin Document Center (głównie), które zostały przejęte po wojnie od Niemców i zdigitalizowane
¶ więcej: https://catalog.archives.gov/id/12044361
Mamy tam m.in. akta #NSDAP #SS i #RuSHA.
Niestety nie jest to baza tekstowa, którą mozna dowolnie przeszukiwać, ale zeskanowane mikfrofilmy są dostępne w formie stron lub zbiorczych pdfów.
Dwie główne kartoteki: A3340-MFKL (centralna kartoteka członków NSDAP) i A3340-MFOK (kartoteka lokalna/geograficzna) mają razem prawie 11mln kart i zawierają takie dane jak :
- imię/nazwisko
- datę urodzenia
- numer partyjny
- datę wstąpienia
- adres
- zawód
Uznaję te akta za niezmiernie ważne z punktu widzenia interesów Polski, więc je gromadzę, a to co się da - zamierzam zindeksować i udostępnić. To są niestety grube gigabajty, analiza ręczna nie wchodzi w grę (11mln kart!), ale może w przyszłości jakieś AI da radę. Ponieważ Niemców bardzo boli fakt dostępności tych akt, tym bardziej zachęca to do działania.
Krótka instrukcja, jak samemu przeglądać:
- Idziemy na https://catalog.archives.gov
- W pole szukania wpisujemy A3340-MFKL (lub inne)
- Sortujemy alfabetycznie (dla porządku)
- Przeglądamy
- Po wejściu w konkretną kartotekę (np A0001), pod przeglądarką stron mamy link do pobrania całego PDFa tego wycinka kartoteki (uwaga: pliki są dość duże!)
- Uważny czytelnik zauważy schemat nazewnictwa plików i ich lokalizacji i będzie w stanie zautomatyzować pobieranie ;)
Gorąco zachęcam do samodzielnej analizy!
O postępach w pracach będę informować na bieżąco, starając się również aktulizować tę stronę.
za: https://x.com/kamienikupa_com/status/2034252233701793993
¶ 2. DANE
Najpierw garść statystyk:
- Baza MFOK: 2169 plików PDF o łącznym rozmiarze 558 GB
- Baza MFKL: 3165 plików i 843 GB
- Średnio w każdym z tych plików jest ponad 3 tysiące stron (łącznie ok. 16 mln), o zmiennej zawartości, ale zawężonej do kilkunastu typów.
- Interesujące nas dane niestety są zarówno w formie maszynopisów, jak i pisma odręcznego w różnorodnym wydaniu - od nieczytelnego 'lekarskiego" po staranną kaligrafię.
- Szacowana liczba osób wykazanych w tych bazach to około 11 milionów.
Z uwagi na ogrom danych ręczna analiza i obróbka jest niemożliwa, więc pozostaje zautomatyzowanie pracy.
Do wyboru w teorii są ścieżki:
- odczyt/ekstrakcja danych do bazy danych
- zaprzęgnięcie AI do pracy, przy udziale farm obliczeniowych na GPU
- to samo, ale na własnych GPU
- obróbka bez AI, zwykły OCR
- podział bazy na logiczne zakresy, prosty indeks biblioteczny
- pozostawienie tego jak jest w obecnej formie w archiwum US
Ekspertem od AI nie jestem, ale patrząc na testy i komentarze osób znających się na tym - ich wnioski są dość zgodne: to nie jest proste zadanie, a dość kosztowne. Zarówno w opcji wykupienia hostingu jak i domowej obróbki (prąd). Do tego - to nie gwarantuje sukcesu, bo sporej części kart nie da się w ten sposób odczytać.
OCR po prostu nie daje sobie rady, wystarczy przejrzeć kilka plików żeby sobie uzmysłowić jakie to karkołomne zadanie.
Ze swojej strony postawiłem na trzecie rozwiązanie, czyli podział bazy na poszczególne karty i udostępnienie ich w formie indeksu bibliotecznego, gdzie zawężając krokowo wybór dochodzimy do listy ~1000 kart z wygodnym przechodzeniem między kartami.
A co z AI? Może kiedyś przyjdzie na to czas, pewnie prościej/szybciej też będzie zacząć obrabiać przygotowane wstępnie dane, zamiast ogromnych plików.
¶ 3. Proces
Przetwarzanie takiej ilości danych musi odbywać się w środowisku serwerowym, tam gdzie dostępna jest większa przestrzen i moc.
Na szczęście dysponuję takową, zatem praca została podzielona na etapy:

- ekstrakcja stron z PDF (zawierających obrazki) do obrazków
- 1 plik to około 3h, na szczęście proces można puszczać równolegle w paru wątkach
- przycinamy ramkę wokół interesującego nas pola, tak żeby ułatwić analizę automatyczną i.. zmniejszyć rozmiar pliku
- automatyczna detekcja i zapis do osobnych plików:
- pustych stron
- obszarów z kartami (1 lub 2)
- wyniki są ręcznie przeglądane, każda usunięta strona jest ręcznie zatwierdzana, weryfikowana też jest poprawność operacji automatycznych
- zatwierdzone dane lecą już w docelowe miejsce, gdzie są odpowiednio dzielone i opisane
¶ 4. Wyniki
Te niestety spływają dosyć wolno. O ile procesy automatycznej analizy można sobie zaprogramować, ale etapu ręcznej weryfikacji i kategoryzacji nie da się przyspieszyć mając do dyspozycji ograniczone zasoby ludzkie (czytaj: siebie) i czasowe.
Zła wiadomość dodatkowo jest taka, że analiza automatyczna dość zmiennego źródła bywa problematyczna. Przy słabym kontraście, przesuniętych marginesach automatyzacja się gubi, dlatego część danych będzie wymagać dalszej obróbki, bo trafiają się zarówno niepodzielone karty, jak i takie przecięte w połowie do dwóch osobnych plików
Ale mimo wszystko, w ciągu paru dni udało się opublikować ponad 93 tysiące obrazów, w ok 80% sprowadzonych do pojedynczej karty. Przy 33 przetworzonych plikach 5 jednak wymaga powtórnego przetworzenia, z uwagi na inne ułożenie kart na stronie (co wyszło w etapie weryfikacji).
Strona z danymi zostanie udostępniona wkrótce, kiedy uzbiera się już trochę więcej zawartości.
A póki co, wygląda to tak:
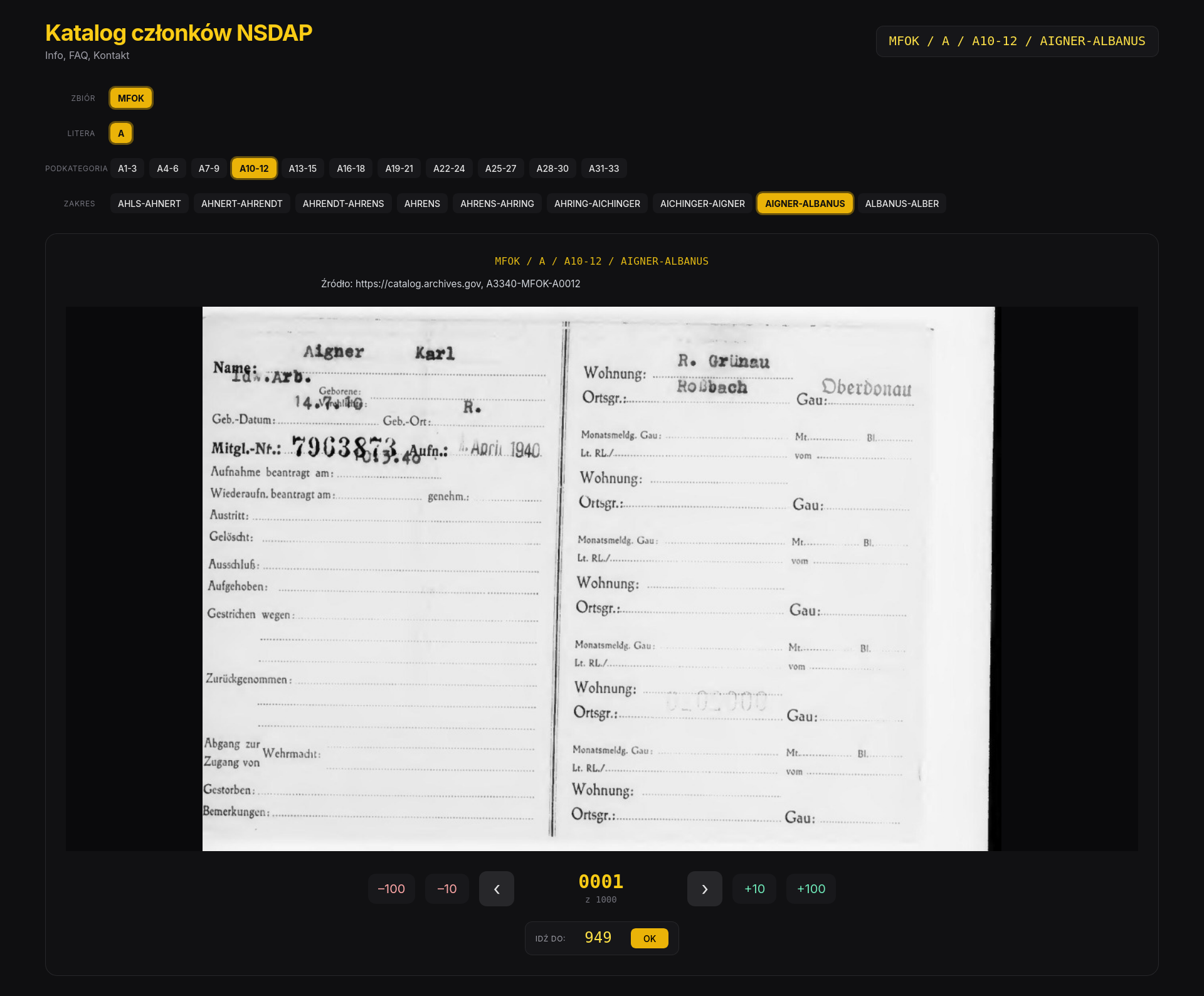
¶ 5. Kontakt
Jeśli chcesz sie skontaktować w jakiejkolwiek sprawie dotyczącej tej bazy: